-
02. JPA Mapping AnnotationBackEnd/JPA 2021. 8. 9. 19:00반응형
Annotation 정의 @Entity JPA가 관리할 객체, JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수
> 기본 생성자 필수(파라미터가 없는 public 또는 protected 생성자), final 클래스, enum, interface, inner 클래스 사용X
(속성)
> name : JPA에서 사용할 엔티티 이름을 지정
(기본값: 클래스 이름을 그대로 사용, 기본값 사용 권장)@Table 엔티티와 매핑할 테이블 지정
(속성)
> name : 매핑할 테이블 이름
(기본값 : 엔티티 이름을 사용)
> catalog : DB catalog 매핑
> schema : DB schema 매핑
> uniqueConstraints(DDL) : DDL 생성 시에 유니크 제약 조건 생성
예) @Table(uniqueConstraints = {@UniqueConstraint( name = "NAME_AGE_UNIQUE",
columnNames = {"NAME", "AGE"} )})@Id 데이터베이스 PK와 매핑 @GeneratedValue 자동 생성
(속성)
> IDENTITY : 데이터베이스에 위임
(주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용)
> SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용
@SequenceGenerator 필요
(오라클, PostgreSQL, DB2, H2 데이터베이스에서 사용)
> TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용
@TableGenerator 필요
> AUTO : 방언에 따라 자동 지정, 기본값
IDENTITY 예)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
SEQUENCE 예)
@Entity
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", // 매핑할 DB 시퀀스명
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;@Column 컬럼 매핑
(속성)
> name : 필드와 매핑할 테이블의 컬럼 이름
(기본값 : 객체의 필드 이름)
> insertable, updatable : 등록, 변경 가능 여부
(기본값 : TRUE)
> nullable(DDL) : null 값의 허용 여부를 설정한다. false로 설정하면 DDL 생성 시에 not null 제약조건이 붙는다.
> unique(DDL) : @Table의 uniqueConstraints와 같지만 한 컬럼에 간단히 유니크 제 약조건을 걸 때 사용한다.
> columnDefinition(DDL) : 데이터베이스 컬럼 정보를 직접 줄 수 있다.
예) varchar(100) default ‘EMPTY'
> length(DDL) : 문자 길이 제약조건, String 타입에만 사용한다.
(기본값 : 255)
> precision, scale(DDL) : BigDecimal 타입에서 사용한다(BigInteger도 사용할 수 있다). precision은 소수점을 포함한 전체 자 릿수를, scale은 소수의 자릿수 다. 참고로 double, float 타입에는 적용되지 않는다. 아주 큰 숫자나 정 밀한 소수를 다루어야 할 때만 사용한다.
(기본값 : precision=19, scale=2)@Temporal 날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용
(속성)
> value
1) TemporalType.DATE: 날짜, 데이터베이스 date 타입과 매핑 (예: 2013–10–11)
2) TemporalType.TIME: 시간, 데이터베이스 time 타입과 매핑 (예: 11:11:11)
3) TemporalType.TIMESTAMP: 날짜와 시간, 데이터베이 스 timestamp 타입과 매핑(예: 2013–10–11 11:11:11)@Enumerated 자바 enum 타입을 매핑할 때 사용
(속성)
> value
1) EnumType.ORDINAL: enum 순서를 데이터베이스에 저장
2) EnumType.STRING: enum 이름을 데이터베이스에 저장
(기본값 : EnumType.ORDINAL) 사용 X@Lob 데이터베이스 BLOB, CLOB 타입과 매핑
> 매핑하는 필드 타입이 문자면 CLOB 매핑, 나머지는 BLOB 매핑
> CLOB: String, char[], java.sql.CLOB
> BLOB: byte[], java.sql. BLOB@Transient 특정 필드를 컬럼에 매핑하지 않음(매핑 무시)
> 필드 매핑X
> DB에 저장/조회 X
> 주로 메모리상에서만 임시로 어떤 값을 보관하고 싶을 때 사용
예) @Transient
private Integer temp;> DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.
tip) DB Schema 자동 생성
> JPA는 방언을 활용해서 DDL을 애플리케이션 실행 시점에 자동으로 생성한다. 이렇게 생성된 DDL은 개발서버에서만 사용하고 운영서버에서는 사용하지 않거나 적절히 다듬은 후 사용해야 한다.
> 설정 : hibernate.hbm2ddl.auto
1) create : 기존테이블 삭제 후 다시 생성 (DROP + CREATE)
2) create-drop : create와 같으나 종료시점에 테이블 DROP
3) update : 변경분만 반영(운영DB에는 사용하면 안됨)
4) validate : 엔티티와 테이블이 정상 매핑되었는지만 확인
5) none : 사용하지 않음
Annotation 정의 @ManyToOne 다대일
> 외래 키가 있는 쪽이 연관관계 주인
> 양쪽을 서로 참조하도록 개발
(속성)
> optional : false로 설정하면 연관된 엔티티가 항상 있어야 한다. (기본값 : TRUE)
> fetch : 글로벌 페치 전략 (기본값 : @ManyToOne=FetchType.EAGER, @OneToMany=FetchType.LAZY)
> cascade : 영속성 전이 기능
> targetEntity : 연관된 엔티티의 타입 정보를 설정한다. 이 기능은 거 의 사용하지 않는다. 컬렉션을 사용해도 제네릭으로 타 입 정보를 알 수 있다.@OneToMany 일대다
> 일대다 단방향은 일대다(1:N)에서 일(1)이 연관관계 주인
> @JoinColumn을 꼭 사용해야 함. 그렇지 않으면 조인 테이블 방식을 사용함(중간에 테이블을 하나 추가함)
(속성)
> mappedBy : 연관관계 주인 필드 선택 (주인은 mappedBy 속성 사용X)
> fetch : 글로벌 페치 전략 (기본값 : @ManyToOne=FetchType.EAGER, @OneToMany=FetchType.LAZY)
> cascade : 영속성 전이 기능
> targetEntity : 연관된 엔티티의 타입 정보를 설정한다. 이 기능은 거 의 사용하지 않는다. 컬렉션을 사용해도 제네릭으로 타 입 정보를 알 수 있다.
(단점)
1. 엔티티가 관리하는 외래 키가 다른 테이블에 있음
2. 연관관계 관리를 위해 추가로 UPDATE SQL 실행
> 다대일 양방향 사용 권장@OneToOne 일대일
> (다대일)처럼 외래 키가 있는 곳이 연관관계 주인
1) 주 테이블에 외래 키
> 주 객체가 대상 객체의 참조를 가지는 것 처럼 주 테이블에 외래 키를 두고 대상 테이블을 찾음
> 객체지향 개발자 선호
> JPA 매핑 편리
> 장점: 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능
> 단점: 값이 없으면 외래 키에 null 허용
2) 대상 테이블에 외래 키
> 대상 테이블에 외래 키가 존재
> 전통적인 데이터베이스 개발자 선호
> 장점: 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지
> 단점: 프록시 기능의 한계로 지연 로딩으로 설정해도 항상 즉시 로딩됨@ManyToMany 다대다
> 객체는 컬렉션을 사용해서 객체 2개로 다대다 관계 가능 하지만, 관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
> 연결 테이블을 추가해서 일대다, 다대일 관계로 풀어내야함
> @JoinTable로 연결 테이블 지정
> 실무 사용 X
@ManyToMany -> @OneToMany, @ManyToOne[연관관계 매핑 고려사항]
1) 단방향, 양방향
> 테이블 : 외래 키 하나로 양쪽 조인 가능 (방향 개념 X)
> 객체 : 참조용 필드가 있는 쪽으로만 참조 가능(한쪽인 경우 단방향, 양쪽인 경우 양방향)
2) 연관관계의 주인
> 외래 키를 관리하는 참조
> 주인의 반대편: 외래 키에 영향을 주지 않음, 단순 조회만 가능
[연관관계 매핑 주의사항]
> 순수 객체 상태를 고려해서 항상 양쪽에 값을 설정하자
> 연관관계 편의 메소드를 생성하자
> 양방향 매핑시에 무한 루프를 조심하자 (예: toString(), lombok, JSON 생성 라이브러리)
> 단방향 매핑만으로도 이미 연관관계 매핑은 완료, 양방향 매핑은 반대 방향으로 조회(객체 그래프 탐색) 기능이 추가된 것 뿐
> 단방향 매핑을 잘 하고 양방향은 필요할 때 추가해도 됨 (테이블에 영향을 주지 않음)
[상속관계 매핑]
1) 각각 테이블로 변환 > 조인 전략
> 테이블 정규화가 가능하나 조회 시 조인을 많이 사용하여 성능 저하 및 데이터 저장 시 INSERT SQL 2번 호출 필요

2) 통합 테이블로 변환 > 단일 테이블 전략
> 조회 쿼리가 단순할 수 있으나 테이블이 커질 수 있는 우려가 있으며 상황에 따라 조회 성능 악화

3) 서브타입 테이블로 변환 > 구현 클래스마다 테이블 전략
> 추천X, 서브 타입을 명확하게 구분해서 처리할 때 효과적
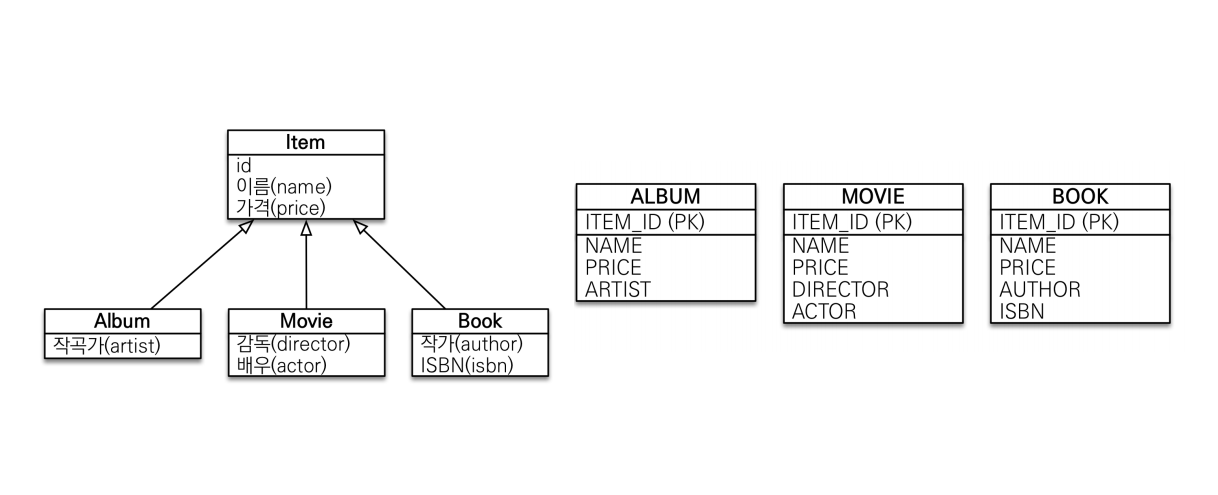
Annotation 정의 @Inheritance(strategy=InheritanceType.XXX) 1) JOINED : 조인 전략
2) SINGLE_TABLE : 단일 테이블 전략
3) TABLE_PER_CLASS: 구현 클래스마다 테이블 전략@DiscriminatorColumn(name=“DTYPE”) 부모 클래스에 선언, 하위 클래스 구분 @DiscriminatorValue(“XXX”) 엔티티 저장 시 구분컬럼에 입력할 값 지정 @MappedSuperclass 공통 매핑 정보가 필요할 때 사용
(등록일, 수정일, 등록자, 수정자)
> 상속관계 매핑X
> 엔티티X, 테이블과 매핑X
> 부모 클래스를 상속 받는 자식 클래스에 매핑 정보만 제공
> 조회, 검색 불가(em.find(BaseEntity) 불가)
> 직접 생성해서 사용할 일이 없으므로 추상 클래스 권장
> 참고 : @Entity 클래스는 엔티티나 @MappedSuperclass로 지 정한 클래스만 상속 가능반응형'BackEnd > JPA' 카테고리의 다른 글
05. JPA 객체지향 쿼리 언어(JPQL) (0) 2021.08.13 04. JPA 값 타입 (0) 2021.08.13 03. JPA 연관관계 관리 (0) 2021.08.13 01. JPA(Java Persistence API) (0) 2021.08.09