-
01. 카프카(Kafka)BackEnd/Kafka 2021. 10. 30. 17:00반응형
들어가기 전 용어를 간략히 정의하면, 데이터 파이프라인이란 데이터를 추출(extracting)하고 변경(transforming), 적재(loading)하는 과정을 묶은 것입니다. 클러스터란 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합이며 카프카의 브로커란 카프카의 서버입니다.
데이터를 생성하고 적재하기 위해서는 데이터를 생성하는 소스 애플리케이션과 데이터가 최종 적재되는 타깃 애플리케이션을 연결해야 합니다. end to end 연결 방식의 아키텍처는 데이터를 전송하는 라인이 기하급수적으로 복잡해지며 확장이 어렵습니다. 또한 1:1 매칭의 데이터 파이프라인은 커플링으로 인해 한쪽의 이슈가 다른 쪽 애플리케이션에 영향을 미칩니다.
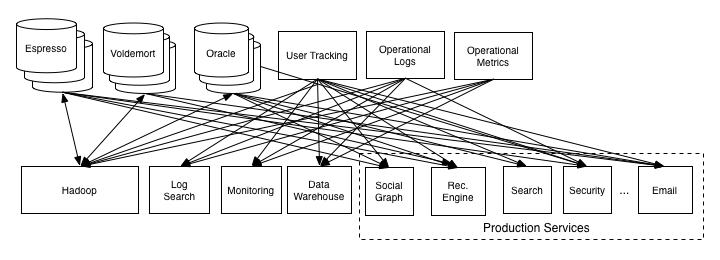
카프카 도입 이전 아키텍처 이를 해결하기 위해 링크드인 데이터팀에서 만든 것이 아파치 카프카(Apache Kafka) 입니다. 카프카는 데이터 처리를 중앙집중화하여 웹사이트, 애플리케이션, 센서 등에서 취합한 데이터 스트림을 한곳에서 실시간으로 관리할 수 있게 하였습니다.

카프카가 적용된 이후의 파이프라인 아키텍처 카프카 특징
- 높은 처리량
많은 양의 데이터를 묶음 단위로 처리하는 배치로 빠르게 처리할 수 있고 동일 목적의 데이터를 여러 파티션에 분배하고 데이터를 병렬처리할 수 있습니다. - 확장성
클러스터의 무중단 운영으로 스케일 아웃(scale-out, 클러스터의 브로커 개수 늘림), 스케일 인(scale-in, 클러스터의 브로커 개수 줄임)을 지원합니다. - 영속성
디스크 기반의 파일 시스템에 데이터를 저장합니다. 그러므로 브로커 애플리케이션이 장애 발생으로 급작스럽게 종료되어도 프로세스를 재시작하여 안전하게 데이터를 처리할 수 있습니다. 운영체제에서는 파일 I/O 성능 향상을 위해 페이지 캐시(page cache) 영역을 메모리에 따로 생성하여 사용합니다. 페이지 캐시 메모리 영역을 사용하여 한번 읽은 파일 내용은 메모리에 저장시켰다가 다시 사용하는 방식이기 때문에 카프카가 파일 시스템에 저장하고 데이터를 저장, 전송하더라도 처리량이 높은 것입니다. - 고가용성
클러스터로 이루어진 카프카는 데이터의의 복제(replication)를 통해 고가용성의 특징을 가집니다. 한 브로커에 장애가 발생하더라도 복제된 데이터가 나머지 브로커에 저장되어 있으므로 저장된 데이터를 기준으로 지속적으로 데이터 처리가 가능한 것입니다.
(참고)
배치 데이터와 스트림 데이터
'배치 데이터'는 초, 분, 시간, 일 등으로 한정된 기간 단위 데이터를 뜻합니다. 배치 데이터를 일괄 처리(batch processing)하는 것이 특징입니다. 반면 '스트림 데이터'는 한정되지 않은 데이터로 시작 데이터와 끝 데이터가 명확히 정해지지 않은 데이터를 뜻합니다. 각 지점의 데이터는 보통 작은 단위(KB 단위)로 쪼개져 있으며 웹 사용자의 클릭 로그, 주식 정보, 사물 인터넷의 센서 데이터를 스트림 데이터로 볼 수 있습니다.
반응형'BackEnd > Kafka' 카테고리의 다른 글
06. 카프카 클라이언트(Kafka Client with JAVA) (0) 2021.11.05 05. 카프카 컨슈머(Kafka Consumer) (1) 2021.11.04 04. 카프카 프로듀서(Kafka Producer) (0) 2021.11.02 03. 토픽(Topic)과 파티션(Partition) (0) 2021.11.02 02. 카프카 아키텍처(Kafka Architecture) (0) 2021.10.30 - 높은 처리량