-
28. 멀티 스레드 프로세싱 (Multi Thread Processing)BackEnd/Spring Batch 2022. 1. 8. 13:40반응형
일반적으로 복잡한 처리나 대용량 데이터를 다루는 작업일 경우, 전체 소요 시간 및 성능상의 이점을 가져오기 위해 멀티 스레드 방식을 선택합니다. 멀티 스레드 처리 방식은 데이터 동기화 이슈가 존재하기 때문에 최대한 고려해서 결정해야 합니다.

Spring Batch Thread Model
- 스프링 배치는 기본적으로 단일 스레드 방식으로 작업을 처리합니다.
- 성능 향상과 대규모 데이터 작업을 위한 비동기 처리 및 Scale out 기능을 제공합니다.
- Local과 Remote 처리를 지원합니다.
1. AsyncItemProcessor / AsyncItemWriter
ItemProcessor, ItemWriter에게 별도의 스레드가 할당되어 작업을 처리하는 방식입니다. Step 안에서 ItemProcessor가 비동기적으로 동작하는 구조로 AsyncItemProcessor와 AsyncItemWriter가 함께 구성되어야 합니다. AsyncItemProcessor로부터 AsyncItemWriter가 받는 최종 결과 값은 List<Future<T>> 타입이며, 비동기 실행이 완료될 때까지 대기합니다.
spring-batch-integration 의존성 추가가 필요합니다.
<dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-integration</artifactId> </dependency>
API

package io.springbatch.springbatchlecture; import lombok.RequiredArgsConstructor; import org.springframework.batch.core.*; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.integration.async.AsyncItemProcessor; import org.springframework.batch.integration.async.AsyncItemWriter; import org.springframework.batch.item.ItemProcessor; import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider; import org.springframework.batch.item.database.JdbcBatchItemWriter; import org.springframework.batch.item.database.JdbcPagingItemReader; import org.springframework.batch.item.database.Order; import org.springframework.batch.item.database.support.MySqlPagingQueryProvider; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.task.SimpleAsyncTaskExecutor; import org.springframework.core.task.TaskExecutor; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import javax.sql.DataSource; import java.util.*; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.ThreadPoolExecutor; @RequiredArgsConstructor @Configuration public class AsyncConfiguration { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; private final DataSource dataSource; @Bean public Job job() throws Exception { return jobBuilderFactory.get("batchJob") .incrementer(new RunIdIncrementer()) // .start(step1()) .start(asyncStep1()) .listener(new StopWatchJobListener()) .build(); } @Bean public Step step1() throws Exception { return stepBuilderFactory.get("step1") .chunk(100) .reader(pagingItemReader()) .processor(customItemProcessor()) .writer(customItemWriter()) .build(); } @Bean public Step asyncStep1() throws Exception { return stepBuilderFactory.get("asyncStep1") .chunk(100) .reader(pagingItemReader()) .processor(asyncItemProcessor()) .writer(asyncItemWriter()) .taskExecutor(taskExecutor()) .build(); } @Bean public JdbcPagingItemReader<Customer> pagingItemReader() { JdbcPagingItemReader<Customer> reader = new JdbcPagingItemReader<>(); reader.setDataSource(this.dataSource); reader.setPageSize(100); reader.setRowMapper(new CustomerRowMapper()); MySqlPagingQueryProvider queryProvider = new MySqlPagingQueryProvider(); queryProvider.setSelectClause("id, firstName, lastName, birthdate"); queryProvider.setFromClause("from customer"); Map<String, Order> sortKeys = new HashMap<>(1); sortKeys.put("id", Order.ASCENDING); queryProvider.setSortKeys(sortKeys); reader.setQueryProvider(queryProvider); return reader; } @Bean public ItemProcessor customItemProcessor() { return new ItemProcessor<Customer, Customer>() { @Override public Customer process(Customer item) throws Exception { Thread.sleep(1000); return new Customer(item.getId(), item.getFirstName().toUpperCase(), item.getLastName().toUpperCase(), item.getBirthdate()); } }; } @Bean public JdbcBatchItemWriter customItemWriter() { JdbcBatchItemWriter<Customer> itemWriter = new JdbcBatchItemWriter<>(); itemWriter.setDataSource(this.dataSource); itemWriter.setSql("insert into customer2 values (:id, :firstName, :lastName, :birthdate)"); itemWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider()); itemWriter.afterPropertiesSet(); return itemWriter; } @Bean public AsyncItemProcessor asyncItemProcessor() throws Exception { AsyncItemProcessor<Customer, Customer> asyncItemProcessor = new AsyncItemProcessor(); asyncItemProcessor.setDelegate(customItemProcessor()); asyncItemProcessor.setTaskExecutor(new SimpleAsyncTaskExecutor()); // asyncItemProcessor.setTaskExecutor(taskExecutor()); asyncItemProcessor.afterPropertiesSet(); return asyncItemProcessor; } @Bean public AsyncItemWriter asyncItemWriter() throws Exception { AsyncItemWriter<Customer> asyncItemWriter = new AsyncItemWriter<>(); asyncItemWriter.setDelegate(customItemWriter()); asyncItemWriter.afterPropertiesSet(); return asyncItemWriter; } @Bean public TaskExecutor taskExecutor(){ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(4); executor.setMaxPoolSize(8); executor.setThreadNamePrefix("async-thread-"); return executor; } }2. Multi-threaded Step
Step 내 Chunk 구조인 ItemReader, ItemProcessor, ItemWriter마다 여러 스레드가 할당되어 실행하는 방식입니다. TaskExecutorRepeatTemplate이 반복자로 사용되며 설정한 개수(throttleLimit) 만큼의 스레드를 생성하여 수행합니다. ItemReader 시 데이터를 중복으로 처리하지 않기 위해 Thread-safe인지 확인이 필요합니다. Thread-safe한 JdbcPagingItemReader, JpaPagingItemReader를 사용하며, TaskExecutor로 SimpleAsyncTaskExecutor를 지원하지만 ThreadPoolTaskExecutor 사용을 권장합니다. Thread-safe 하지 않은 ItemReader를 Thread-safe하게 처리하도록 하기 위해서는 SynchronizedItemStreamReader(Spring Batch 4.0부터 지원)를 사용합니다.

API

package io.springbatch.springbatchlecture; import lombok.RequiredArgsConstructor; import org.springframework.batch.core.*; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.integration.async.AsyncItemProcessor; import org.springframework.batch.integration.async.AsyncItemWriter; import org.springframework.batch.item.ItemProcessor; import org.springframework.batch.item.database.*; import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder; import org.springframework.batch.item.database.support.MySqlPagingQueryProvider; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.task.SimpleAsyncTaskExecutor; import org.springframework.core.task.TaskExecutor; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import javax.sql.DataSource; import java.util.*; @RequiredArgsConstructor @Configuration public class MultiThreadStepConfiguration { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; private final DataSource dataSource; @Bean public Job job() throws Exception { return jobBuilderFactory.get("batchJob") .incrementer(new RunIdIncrementer()) .start(step1()) .listener(new StopWatchJobListener()) .build(); } @Bean public Step step1() throws Exception { return stepBuilderFactory.get("step1") .<Customer, Customer>chunk(100) .reader(pagingItemReader()) .listener(new CustomReadListener()) .processor((ItemProcessor<Customer, Customer>) item -> item) .listener(new CustomProcessListener()) .writer(customItemWriter()) .listener(new CustomWriteListener()) .taskExecutor(taskExecutor()) // .taskExecutor(new SimpleAsyncTaskExecutor()) // .throttleLimit(2) .build(); } @Bean public JdbcCursorItemReader<Customer> customItemReader() { return new JdbcCursorItemReaderBuilder() .name("jdbcCursorItemReader") .fetchSize(100) .sql("select id, firstName, lastName, birthdate from customer order by id") .beanRowMapper(Customer.class) .dataSource(dataSource) .build(); } @Bean public JdbcPagingItemReader<Customer> pagingItemReader() { JdbcPagingItemReader<Customer> reader = new JdbcPagingItemReader<>(); reader.setDataSource(this.dataSource); reader.setPageSize(100); reader.setRowMapper(new CustomerRowMapper()); MySqlPagingQueryProvider queryProvider = new MySqlPagingQueryProvider(); queryProvider.setSelectClause("id, firstName, lastName, birthdate"); queryProvider.setFromClause("from customer"); Map<String, Order> sortKeys = new HashMap<>(1); sortKeys.put("id", Order.ASCENDING); queryProvider.setSortKeys(sortKeys); reader.setQueryProvider(queryProvider); return reader; } @Bean public JdbcBatchItemWriter customItemWriter() { JdbcBatchItemWriter<Customer> itemWriter = new JdbcBatchItemWriter<>(); itemWriter.setDataSource(this.dataSource); itemWriter.setSql("insert into customer2 values (:id, :firstName, :lastName, :birthdate)"); itemWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider()); itemWriter.afterPropertiesSet(); return itemWriter; } @Bean public TaskExecutor taskExecutor(){ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(4); executor.setMaxPoolSize(8); executor.setThreadNamePrefix("async-thread-"); return executor; } }SynchronizedItemStreamReader
SynchronizedItemStreamReader는 Thread-safe 하지 않은 ItemReader를 Thread-safe하게 처리합니다.

import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.batch.core.ItemReadListener; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepScope; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider; import org.springframework.batch.item.database.JdbcBatchItemWriter; import org.springframework.batch.item.database.JdbcCursorItemReader; import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder; import org.springframework.batch.item.support.SynchronizedItemStreamReader; import org.springframework.batch.item.support.builder.SynchronizedItemStreamReaderBuilder; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.task.TaskExecutor; import org.springframework.jdbc.core.BeanPropertyRowMapper; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import javax.sql.DataSource; @RequiredArgsConstructor @Configuration @Slf4j public class SynchronizedConfiguration { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; private final DataSource dataSource; @Bean public Job job() throws Exception { return jobBuilderFactory.get("batchJob") .incrementer(new RunIdIncrementer()) .start(step1()) .build(); } @Bean public Step step1() { return stepBuilderFactory.get("step1") .<Customer, Customer>chunk(60) .reader(customItemReader()) .writer(customerItemWriter()) .taskExecutor(taskExecutor()) .build(); } @Bean @StepScope public SynchronizedItemStreamReader<Customer> customItemReader() { JdbcCursorItemReader<Customer> notSafetyReader = new JdbcCursorItemReaderBuilder<Customer>() .fetchSize(60) .dataSource(dataSource) .rowMapper(new BeanPropertyRowMapper<>(Customer.class)) .sql("select id, firstName, lastName, birthdate from customer") .name("SafetyReader") .build(); return new SynchronizedItemStreamReaderBuilder<Customer>() .delegate(notSafetyReader) .build(); } @Bean @StepScope public JdbcBatchItemWriter<Customer> customerItemWriter() { JdbcBatchItemWriter<Customer> itemWriter = new JdbcBatchItemWriter<>(); itemWriter.setDataSource(this.dataSource); itemWriter.setSql("insert into customer2 values (:id, :firstName, :lastName, :birthdate)"); itemWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider()); itemWriter.afterPropertiesSet(); return itemWriter; } @Bean public TaskExecutor taskExecutor(){ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(4); executor.setMaxPoolSize(8); executor.setThreadNamePrefix("safety-thread-"); return executor; } }3. Parallel Steps
Step마다 스레드가 할당되어 여러개의 Step을 병렬로 실행하는 방식으로 SplitState를 사용해서 여러 개의 Flow들을 병렬적으로 실행하는 구조입니다. 실행이 다 완료된 후에는 FlowExecutionStatus 결과들을 취합해서 다음 단계를 결정합니다.

API

package io.springbatch.springbatchlecture; import lombok.RequiredArgsConstructor; import org.springframework.batch.core.*; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.job.builder.FlowBuilder; import org.springframework.batch.core.job.flow.Flow; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.core.step.tasklet.Tasklet; import org.springframework.batch.core.step.tasklet.TaskletStep; import org.springframework.batch.integration.async.AsyncItemProcessor; import org.springframework.batch.integration.async.AsyncItemWriter; import org.springframework.batch.item.ItemProcessor; import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider; import org.springframework.batch.item.database.JdbcBatchItemWriter; import org.springframework.batch.item.database.JdbcPagingItemReader; import org.springframework.batch.item.database.Order; import org.springframework.batch.item.database.support.MySqlPagingQueryProvider; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.task.SimpleAsyncTaskExecutor; import org.springframework.core.task.TaskExecutor; import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor; import javax.sql.DataSource; import java.util.*; @RequiredArgsConstructor @Configuration public class ParallelStepConfiguration { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; @Bean public Job job() { return jobBuilderFactory.get("batchJob") .incrementer(new RunIdIncrementer()) .start(flow1()) .split(taskExecutor()).add(flow2()) .end() .listener(new StopWatchJobListener()) .build(); } @Bean public Flow flow1() { TaskletStep step = stepBuilderFactory.get("step1") .tasklet(tasklet()).build(); return new FlowBuilder<Flow>("flow1") .start(step) .build(); } @Bean public Flow flow2() { TaskletStep step1 = stepBuilderFactory.get("step2") .tasklet(tasklet()).build(); TaskletStep step2 = stepBuilderFactory.get("step3") .tasklet(tasklet()).build(); return new FlowBuilder<Flow>("flow2") .start(step1) .next(step2) .build(); } @Bean public Tasklet tasklet() { return new CustomTasklet(); } @Bean public TaskExecutor taskExecutor(){ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); executor.setCorePoolSize(2); executor.setMaxPoolSize(4); executor.setThreadNamePrefix("async-thread-"); return executor; } }4. Partitioning
Master/Slave 방식으로 Master가 데이터를 파티셔닝 한 다음 각 파티션에게 스레드를 할당하여 Slave가 독립적으로 작동하는 방식입니다. MasterStep은 PartitionStep이며 SlaveStep은 TaskletStep, FlowStep 등이 올 수 있습니다. SlaveStep은 독립적인 StepExecution 파라미터 환경을 구성하며, ItemReader / ItemProcessor / ItemWriter 등을 가지고 작업을 독립적으로 병렬 처리합니다.
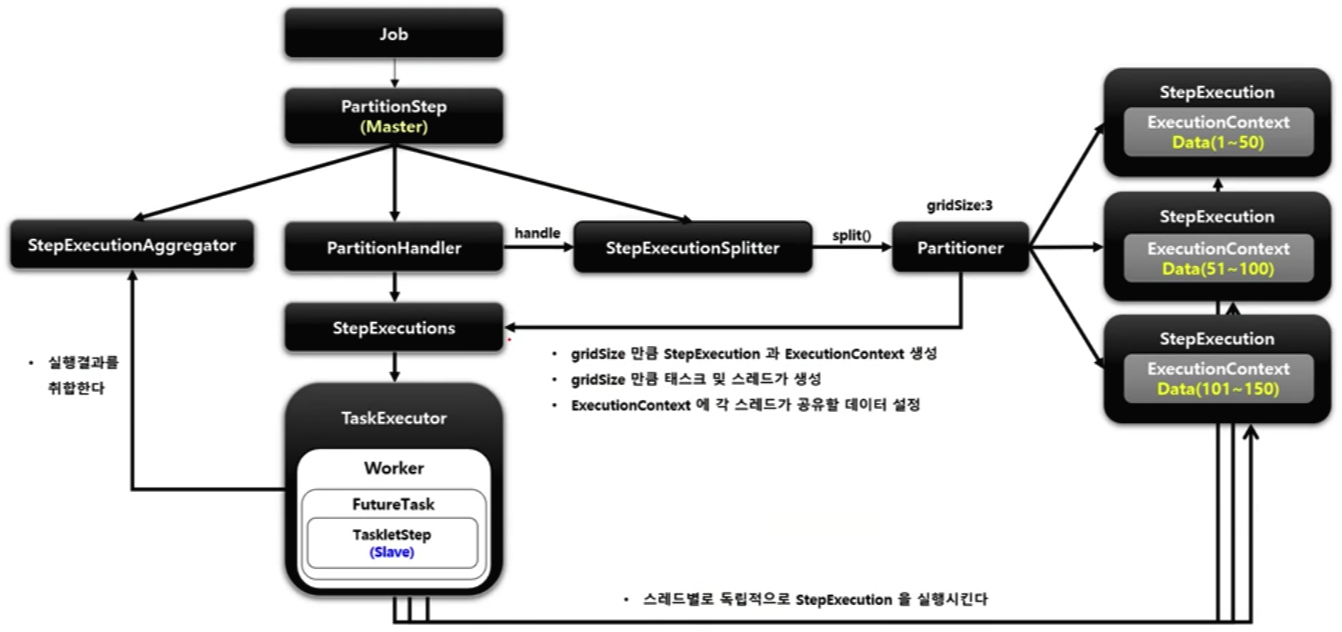

PartitionStep
파티셔닝 기능을 수행하는 Step 구현체입니다. 파티셔닝을 수행한 후 StepExecutionAggregator를 사용해서 StepExecution의 정보를 최종 집계합니다.
PartitionHandler
PartitionStep에 의해 호출되며 스레드를 생성해서 WorkStep을 병렬로 실행합니다. WorkStep에서 사용할 StepExecution 생성은 StepExecutionSplitter와 Partitioner에게 위임합니다. WorkStep을 병렬로 실행한 후 최종 결과를 담은 StepExecution을 PartitionStep에 반환합니다.
StepExecutionSplitter
WorkStep에서 사용할 StepExecution을 gridSize만큼 생성합니다. Partitioner를 통해 ExecutionContext를 얻어서 StepExecution에 매핑합니다.
Partitioner
StepExecution에 매핑할 ExecutionContext를 gridSize만큼 생성합니다. 각 ExecutionContext에 저장된 정보는 WorkStep을 실행하는 스레드마다 독립적으로 참조 및 활용이 가능합니다.
API

package io.springbatch.springbatchlecture; import lombok.RequiredArgsConstructor; import org.springframework.batch.core.Job; import org.springframework.batch.core.Step; import org.springframework.batch.core.configuration.annotation.JobBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepBuilderFactory; import org.springframework.batch.core.configuration.annotation.StepScope; import org.springframework.batch.core.launch.support.RunIdIncrementer; import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider; import org.springframework.batch.item.database.JdbcBatchItemWriter; import org.springframework.batch.item.database.JdbcPagingItemReader; import org.springframework.batch.item.database.Order; import org.springframework.batch.item.database.support.MySqlPagingQueryProvider; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.core.task.SimpleAsyncTaskExecutor; import javax.sql.DataSource; import java.util.HashMap; import java.util.Map; @RequiredArgsConstructor @Configuration public class PartitioningConfiguration { private final JobBuilderFactory jobBuilderFactory; private final StepBuilderFactory stepBuilderFactory; private final DataSource dataSource; @Bean public Job job() throws Exception { return jobBuilderFactory.get("batchJob") .incrementer(new RunIdIncrementer()) .start(masterStep()) .build(); } @Bean public Step masterStep() throws Exception { return stepBuilderFactory.get("masterStep") .partitioner(slaveStep().getName(), partitioner()) .step(slaveStep()) .gridSize(4) .taskExecutor(new SimpleAsyncTaskExecutor()) .build(); } @Bean public Step slaveStep() { return stepBuilderFactory.get("slaveStep") .<Customer, Customer>chunk(1000) .reader(pagingItemReader(null, null)) .writer(customerItemWriter()) .build(); } @Bean public ColumnRangePartitioner partitioner() { ColumnRangePartitioner columnRangePartitioner = new ColumnRangePartitioner(); columnRangePartitioner.setColumn("id"); columnRangePartitioner.setDataSource(this.dataSource); columnRangePartitioner.setTable("customer"); return columnRangePartitioner; } @Bean @StepScope public JdbcPagingItemReader<Customer> pagingItemReader( @Value("#{stepExecutionContext['minValue']}")Long minValue, @Value("#{stepExecutionContext['maxValue']}")Long maxValue) { System.out.println("reading " + minValue + " to " + maxValue); JdbcPagingItemReader<Customer> reader = new JdbcPagingItemReader<>(); reader.setDataSource(this.dataSource); reader.setFetchSize(1000); reader.setRowMapper(new CustomerRowMapper()); MySqlPagingQueryProvider queryProvider = new MySqlPagingQueryProvider(); queryProvider.setSelectClause("id, firstName, lastName, birthdate"); queryProvider.setFromClause("from customer"); queryProvider.setWhereClause("where id >= " + minValue + " and id < " + maxValue); Map<String, Order> sortKeys = new HashMap<>(1); sortKeys.put("id", Order.ASCENDING); queryProvider.setSortKeys(sortKeys); reader.setQueryProvider(queryProvider); return reader; } @Bean @StepScope public JdbcBatchItemWriter<Customer> customerItemWriter() { JdbcBatchItemWriter<Customer> itemWriter = new JdbcBatchItemWriter<>(); itemWriter.setDataSource(this.dataSource); itemWriter.setSql("insert into customer2 values (:id, :firstName, :lastName, :birthdate)"); itemWriter.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider()); itemWriter.afterPropertiesSet(); return itemWriter; } }package io.springbatch.springbatchlecture; import java.util.HashMap; import java.util.Map; import javax.sql.DataSource; import org.springframework.batch.core.partition.support.Partitioner; import org.springframework.batch.item.ExecutionContext; import org.springframework.jdbc.core.JdbcOperations; import org.springframework.jdbc.core.JdbcTemplate; public class ColumnRangePartitioner implements Partitioner { private JdbcOperations jdbcTemplate; private String table; private String column; public void setTable(String table) { this.table = table; } public void setColumn(String column) { this.column = column; } public void setDataSource(DataSource dataSource) { jdbcTemplate = new JdbcTemplate(dataSource); } @Override public Map<String, ExecutionContext> partition(int gridSize) { int min = jdbcTemplate.queryForObject("SELECT MIN(" + column + ") from " + table, Integer.class); int max = jdbcTemplate.queryForObject("SELECT MAX(" + column + ") from " + table, Integer.class); int targetSize = (max - min) / gridSize + 1; Map<String, ExecutionContext> result = new HashMap<String, ExecutionContext>(); int number = 0; int start = min; int end = start + targetSize - 1; while (start <= max) { ExecutionContext value = new ExecutionContext(); result.put("partition" + number, value); if (end >= max) { end = max; } value.putInt("minValue", start); value.putInt("maxValue", end); start += targetSize; end += targetSize; number++; } return result; } }[참고자료]
반응형'BackEnd > Spring Batch' 카테고리의 다른 글
30. Spring Batch Test (1) 2022.01.14 29. 리스너 (Listener) (0) 2022.01.13 27. Skip & Retry Architect (0) 2022.01.07 26. Retry (0) 2022.01.07 25. Skip (0) 2022.01.06